Keith Matthews
I wear lots of hats, checkout these projects!
Project maintained by kmatthews123 Hosted on GitHub Pages — Theme by mattgraham
Creating a series of ansible playbooks to log stuff
Goal
As far as logging goes, I have largely left things to my fellows in the u-space. They have done some excellent work with grafana and Prometheus to keep an eye on stats relevant to devices in our cluster. This includes scrolling logs for containers, network infrastructure, firewall events, and other types of logs. I find these logs to be very useful when it comes to tracing issues but not terribly useful for monitoring critical metrics such as ensuring updates, and checking in on disk utilization and system hardness.
This movement from running logs to a daily report for select users helps me keep an eye on selected systems and Identify issues with systems in a more active way. I think that this helps prevent alert fatigue if the alerts are only once a day and critical. I think of it like reading the news.
Checkout the code!
- File systems
- Lynis
- Ansible Auto Patching article here
The logs I’m targeting
The three logs I’m generating right now are as follows
- File system usage
- hardening status
- update status These three reports get pushed in different ways. For right now the File system usage and the hardening status reports get generated as needed. Ill probably move these into a once a week readout for review. I do want to use the hardening status report to inform setting up some more robust security settings on the servers we monitor. I also am sure that the file system usage can be monitored better by a smtp tool like cacti or grafana but I haven’t dug into how that works with alerting techniques like using webhooks to alert to issues with systems. For now here are my notes on these scripts.
File system usage
This ansible script uses the pydf tool to run a check on all host systems targeted by ansible. the goal here is to identify any outliers with root file systems that are either getting full unusual quickly or that may not have their full logical volume provisioned like a file system that is 80% full but only has the first 100Gib of a 500Gib disk set up for the file system to use. This helps me as a system admin identify systems that are incorrectly provisioned so I can get in and solve the problem before they fill up and become a problem for users. It also helps me get in front of storage issues like NFS volumes for docker containers that are getting too full.
The report for this command gets generated as an html document that encapsulates all systems. Im using the ansi2html python tool to convert all the readouts to a nice html file to be served.

Truthfully this method is a bit of a hack. It relys on ansible.builtin.shell which is not the most clean way of running playbooks and is also probably less useful than active monitoring. This playbook is useful mostly for quick checks if you’ve got ansible up but no other monitoring.
System hardening
This playbook relies on the lynis software tool. I mostly plan on using this tool as a check on steps I take to harden servers using ansible. The other portion of its use will be to ensure systems managed by others but on systems I’m responsible for are adhering to a minimum level of security. I should probably look into ways to make the output a bit more brief for the security scan portion of this tool since I likely wont need all the recommended stuff that gets added and the links to remediation steps for when I run it against systems.
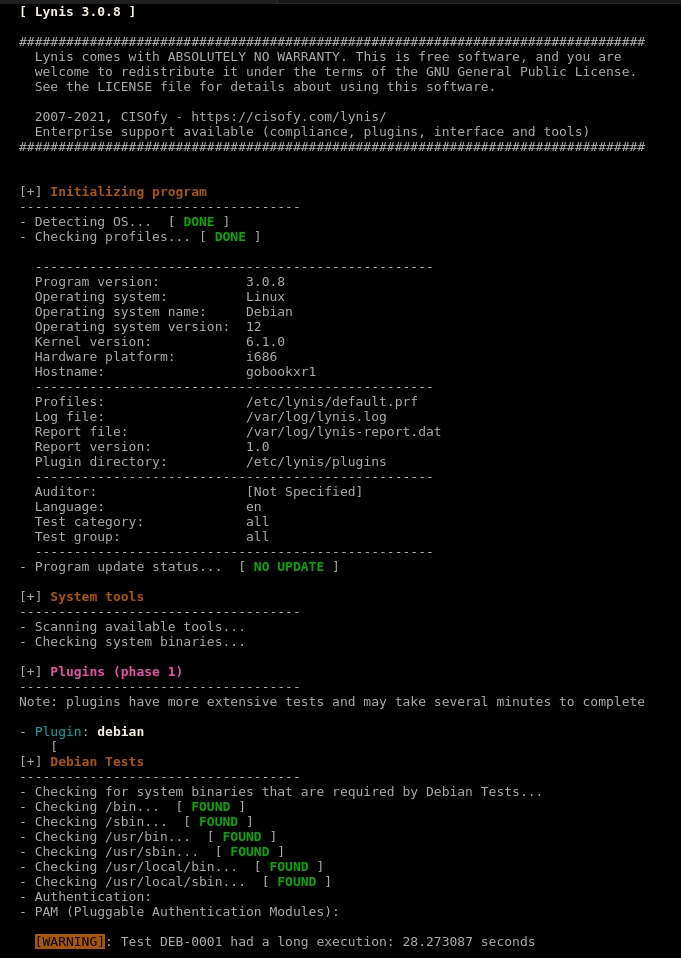
This report usually gets generated as an ansi style message output by a command line. All I really do here is pipe it though a python tool to turn it into an html document with all the colors maintained.
Daily updates
This report is likely going to be tweaked a bit from my post on ansible updates. Mostly that change will be in a change on how the reports are generated. Currently, the combined log that gets pushed out informs the admin monitoring of updated packages and any systems that require reboots. While this is fine, my mentor pointed out to me that normally, the way these things are handled is that an alert will go to a communally monitored channel every day that things have gone well with whatever task. That task in this case is the update having run. If an admin wants more detail they can click that alert and be taken to a report. However, there is no action required. The other options are an alert that things did not go as expected and a relevant party should be notified that they need to attend to whatever did not go properly. The last option is that no alert is triggered. this is also relevant because if there is an alert that’s expected every day at 0900 but no alert is triggered, someone should probably go and investigate.
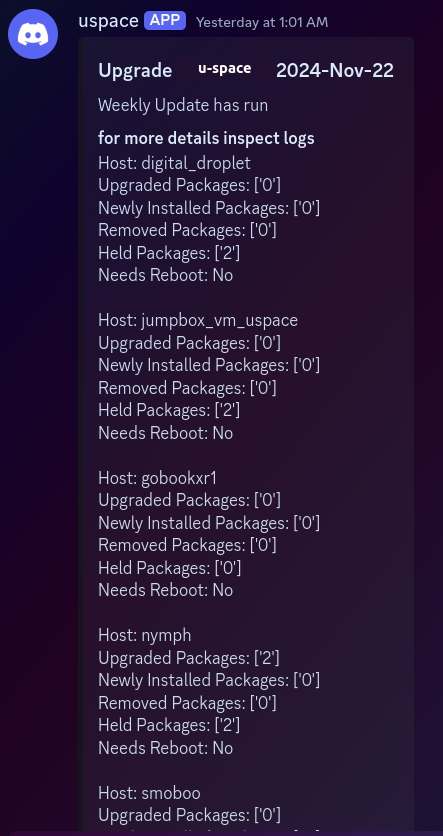
Until I fix things I think this is a good general alert. It keeps me up to date and we don’t have as many folks with eyes on this infrastructure. I think that if this sort of tool gets implemented on the raspberry pi clubs proxmox cluster we will likely have to implement a more streamlined method.